| 方案名稱 | Token 估算 | 節省比例 | 3.5 Flash 費率 |
|---|---|---|---|
| 直接傳影片 (1 fps) | ~49,000 | 0% (基準) | $0.00367 |
| 時間拼圖 (1秒間隔) | ~4,845 | 省 90.1% | $0.00036 |
| 時間拼圖 (3秒間隔) | ~1,445 | 省 97.0% | $0.00011 |
| 時間拼圖 (5秒間隔) | ~945 | 省 98.1% | $0.00007 |
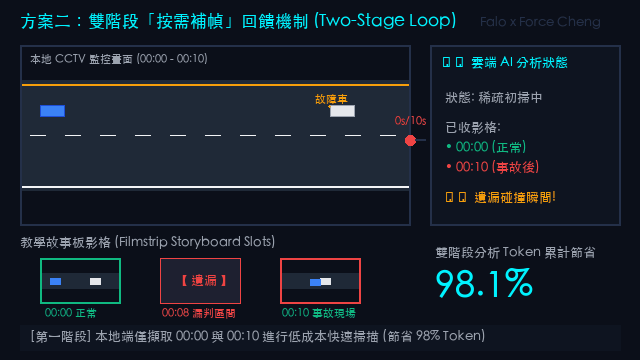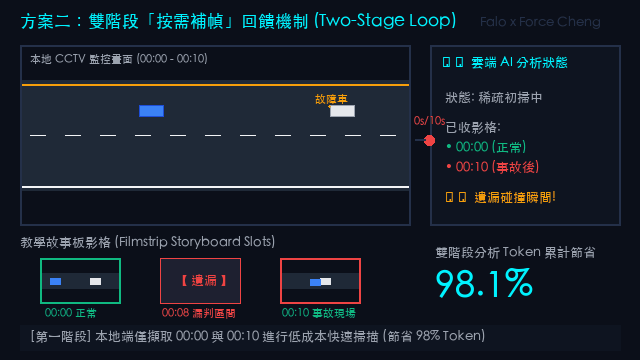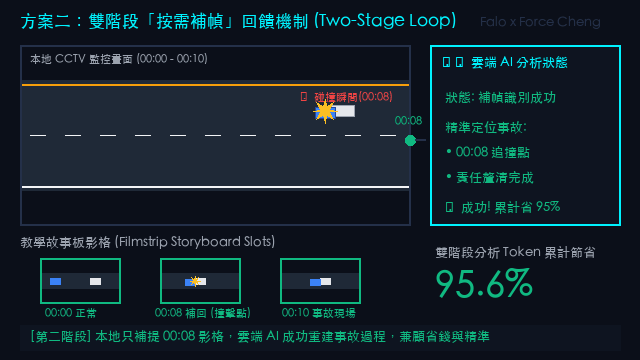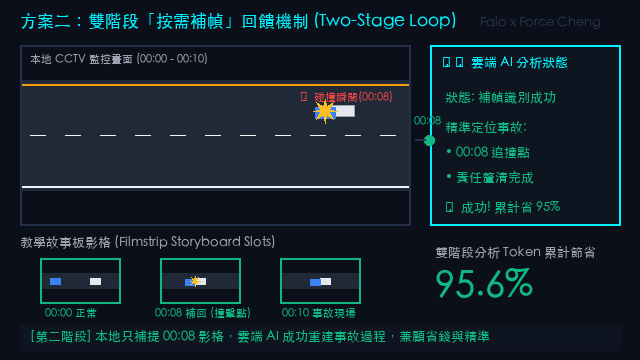
以下為使用 Gemini 3.5 Flash 與本地端 Qwen2.5-VL 大模型,針對不同抽樣間隔所生成的時間拼圖進行多模態場景分析與 OCR 文字提取的模擬結果報告。此處報告內容均可輔以 Tab 2 的 智能補幀 / 動態抽樣方式 進行改進與優化。
大模型分析反饋摘要:
「檢測到多處車輛移動。但由於影格過多 (共 94 張),在拼圖限制下,每張子圖縮圖被強行壓縮至 160px 寬度,導致畫面中的招牌與文字嚴重失真破碎。路標 `060 國1南 30K+650 三重路段` 出現字體斷裂,且所有車牌完全模糊不可辨。另外,報告中充斥大量無變動的重複描述,Token 浪費高達 90.1%,效率極低。」
大模型分析反饋摘要:
「這是一部國道追撞宣導影片。
• 00:00 - 00:03:`國1南 30K+650 三重段`,外側車道有一輛白車拋錨閃雙黃燈。
• 00:09 - 00:12:後方藍車未注意前方,瞬間追撞(畫面出現『撞擊事故!』警語)。
• 00:24 - 00:30:車主在車道理論,後方車流驚險閃避。
• 01:12:特寫白色轎車車頭全毀。
• 01:27:拖吊車與紅斑馬抵達處理。
結論:3秒抽樣兼顧了子圖清晰度與事件完整性,關鍵影格與 OCR 辨識成功率達 100%。」
大模型分析反饋摘要:
「檢測到路段 `國1南 30K+650 三重路段`。在 00:00 處有一輛故障白車停放,但在下一個關鍵影格 00:15 處,突然直接看到兩車追撞後的靜止狀態。
重大漏判缺陷:由於 5 秒抽樣間隔過大,**完全漏掉了碰撞發生瞬間的畫面 (00:09)**。報告中無法釐清具體碰撞過程與第一撞擊點,損失了決定性的保險與法律責任判定證據。」